



Software production is the systematic process of developing software systems. Source code is thereby the material of which software systems are built. Hence, at the heart of software production is the work with code. In this article, we elaborate on the limitations of static code analysis as a means to optimize software production and advocate for a more holistic approach that places CODING at the center of consideration instead of CODE.
Nowadays, software production is often compared with hardware production. As such, there are attempts to borrow concepts for measuring and optimizing hardware factories and transfer them to "software factories". This is generally a good approach, because it helps evolving software development from a crafting discipline to a highly systematic production process that is measured and continuously optimized.
However, one must be aware that the hardware factory metaphor has its limitations. There are fundamental differences between hardware production and software production.
The intellectual part of hardware production is not happening in the factory. It happens in the so-called preproduction or prototyping process. The output of preproduction is a fine-granular process description of how the hardware factory shall convert raw material as input into assembled systems as output. A hardware factory is hence at its core about a mechanical process.
In software production there is also a counterpart to the mechanical assembly in a hardware factory: the build process that converts source code to executable software. Please note that we do not want to use the software factory metaphor to describe the software build process. By this, we would shift the focus to a phase in software production that is already profoundly solved and optimized. Build automation is state-of-the-art since the 1990s and the challenges to setup CI/CD (continuous integration and continuous deployment) properly are trivial compared to the real challenge, which is: Assuring an optimal use of the costliest and scarcest resource in software production – the time of the developers.
We use the factory metaphor to focus on the challenging part of software development: the intellectual work of software developers who convert requirements/specifications into code.

Static code analysis refers to methods that analyze code with respect to structural aspects. The purpose of static code analysis is not to check whether a software system behaves as expected at runtime. Such analysis is performed by dynamic analysis or testing. Just as we have excluded "build automation" from the scope of the software factory metaphor, we also exclude everything related to runtime behavior from the scope. We do this here in this article to avoid defocusing from the real challenge in a software factory: the optimal use of developer time.
To better understand the aim of static code analysis, let's look at its counterpart in hardware production. For this, imagine a hardware factory that produces radios. Then static code analysis would be checking the structural quality of the assembled radio. Are resistors, capacitors and wires soldered well?
In short: Static code analysis is about the structural quality of the delivered output of the software factory, but it won't help to gain insight into the production process itself and is not capable to avoid inefficient use of developer time. Fittingly, also in hardware production no one would try to optimize the production process by just looking at the radios that are delivered out of the factory.
Above, we have discussed conceptual differences between hardware and software factory. There is one more difference: The hardware production process is a linear process that always starts from scratch. Input is converted to output. Simple. Software production, however, is an iterative process where every production cycle happens on the same material. New requirements as input are built into an evolving code base.
The hardware factory metaphor breaks unfortunately when taking the iterative character of software production into account. Such a hardware factory would only produce one single radio and re-solder and re-wire the radio in each production cycle. But let's image such an unusual radio factory. Then, static code analysis would be about checking how well capacitors, resistors, and wires are soldered. But it would also be about another aspect of the structural quality: the understandability of the inner structure of the radio.
A mechanical engineer with the requirement to add Bluetooth capabilities to the radio would work very slowly and cautiously if being confronted with a spaghetti-like wire chaos inside the radio. And this is exactly what software developers experience when they "open" a code base that lacks an understandable inner structure: too large and monolithic code units (circuit boards) with wide-spread dependencies (wires) and long methods with undocumented complex if-else structures (electronics elements where engineers must reverse-engineer their purpose und functions).
Why is a code base not immediately refactored and cleaned up, if it is so obvious that it a complex inner structure has such a negative impact on the factory performance? The reasoning is:
Hence, the problem is a communication problem between the business side and the development side. The term "technical debt" was born from this dilemma. The development side tries to explain in the language of the business side (money) that future problems are being accumulated. Unfortunately, the technical debt concept has shortcomings:
Consequently, using static code analysis to identify code areas that are difficult to understand is not enough. The problem is to present much more striking arguments to the business side to convince them to go without some of their feature wishes and allow for refactorings. Showing the number of rule violations found by a static analysis tool is usually a very unpersuasive argument.
Because of the conflicting objectives between business and developers, static code analysis is usually brought into software development at a part of the process that is entirely within the realm of the development side: the definition of coding rules. Here however, static code analysis can only help keeping the status-quo, i.e., no new coding rule violations. Any investment in the removal of existing rule violations would require a “negotiation” with the business side.
As you have seen in the previous section: Static code analysis is conceptionally not a suitable way to create insights into the software production process itself. Hence, it cannot help to ensure an optimal use of the time of the developers, the scarcest resource in the production process. What now? The answer is straight-forward: Changing perspective. Shifting the focus from code to coding and measuring directly how software developer time is used. The approach sounds easy but is difficult in practice. Reasons are manifold:
Hence, a solution that measures efficient use of developer time cannot rely on time tracking information. What other data could be taken as an approximation of time?
Luckily, an analytics-based approach has been invented recently that overcomes the above-mentioned obstacles. With it, the flow of developer time can be reconstructed from the technical data traces that are already automatically collected in the software development infrastructure tools such as code versioning systems (Git, Subversion, MKS, Mercurial, ClearCase, …).
Interestingly, despite the fact that the analytics approach reconstructs the flow of developer time from activities of software developers, it does not require to know who each developer is. That is, no personal related data is processed. It is somehow the proverbial "squaring the circle": The ability to see developer time flowing without the ability to track individual developer behavior. We emphasize this, because an approach with which the performance of individual developers could be tracked would be a no-go for workers' councils in Europe.
With the information about the flow of developer time, we can add more analytics methods to reveal inefficiencies in the software production process. The following graph shows how developer time is consumed by various inefficiencies and only a fraction of the developer time remains for business value creation. Inefficiencies include:
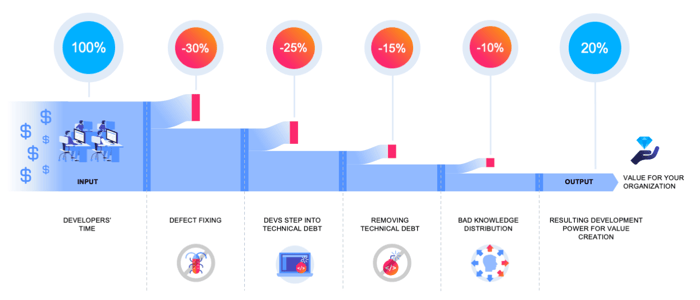
Being able to quantify the efficiency of a software factory with such KPIs enables the management as well as the contributing teams to locate inefficiencies and drive the organization towards less loss. In practice, software factories – compared to hardware factories – often operate at a low level of efficiency and have a huge optimization potential. The reason is that until now there was no analytical approach to measure efficiency in software production.
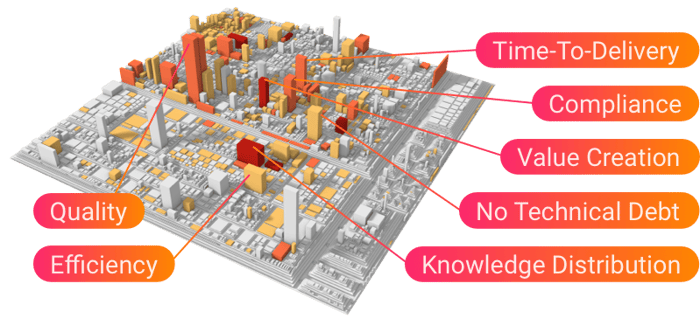
A further advantage of this data-driven approach is that the insights are derived from technical raw data. Hence, we can trace back the root causes of inefficiencies by navigating into the technical data details. For example, we can identify where defect fixing activities take place in the code architecture. By this, the software architects and team leads have a precise x-ray picture where problematic hotspots exist in the code. A powerful and striking way to reveal hotspots in the code architecture is to visualize code as city. Buildings are code units, and the city structure mirrors the technical module structure. Height and color of the code buildings are used to depict inefficiency KPIs; for example the amount of developer time spent for defect fixing in the code building.
The advantage of such a visualization is that technical information can be interpreted both by the technical code experts as well as by managers. It helps to bridge the communication gap between business and development sides (see section above).
The analytics approach works on two levels:
As a result, the analytics approach enables software factories for the first time to establish a data-driven continuous improvement cycle, where "becoming better" is seamlessly embedded into the daily doing of the software factory and the analytics-based insights and KPIs ensure that the factory steers towards higher and higher production excellence.