



Softwareproduktion ist der systematische Vorgang der Entwicklung von Softwaresystemen. Der Quellcode ist dabei das Material, aus dem Softwaresysteme gebaut werden. Das Herzstück der Softwareproduktion ist also die Arbeit am Code. In diesem Artikel gehen wir auf die Grenzen der statischen Codeanalyse als Mittel zur Optimierung der Softwareproduktion ein und plädieren für einen ganzheitlicheren Ansatz, der nicht den CODE, sondern den CODING in den Mittelpunkt der Betrachtung stellt.
Heutzutage wird die Softwareproduktion oft mit der Hardwareproduktion verglichen. So wird versucht, Konzepte zur Messung und Optimierung von Hardware-Fabriken zu übertragen und auf "Software-Fabriken" anzuwenden. Dies ist im Allgemeinen ein guter Ansatz, da er dazu beiträgt, die Softwareentwicklung von einer handwerklichen Disziplin zu einem hoch systematischen Produktionsprozess zu entwickeln, der gemessen und kontinuierlich optimiert wird.
Man muss sich jedoch darüber im Klaren sein, dass die Metapher der Hardware-Fabrik ihre Grenzen hat. Es gibt grundlegende Unterschiede zwischen der Hardwareproduktion und der Softwareproduktion.
Der intellektuelle Teil der Hardwareproduktion findet nicht in der Fabrik statt. Er findet im so genannten Vorproduktions- oder Prototyping-Prozess statt. Das Ergebnis der Vorproduktion ist eine feingranulare Prozessbeschreibung, wie die Hardwarefabrik Rohmaterial als Input in zusammengesetzte Systeme als Output umwandeln soll. Bei einer Hardware-Fabrik handelt es sich also im Kern um einen mechanischen Prozess.
In der Softwareproduktion gibt es auch ein Gegenstück zur mechanischen Montage in einer Hardwarefabrik: den Build-Prozess, der den Quellcode in ausführbare Software umwandelt. Bitte bedenken Sie, dass wir die Metapher der Softwarefabrik nicht verwenden wollen, um den Softwareerstellungsprozess zu beschreiben. Damit würden wir den Schwerpunkt auf eine Phase der Softwareproduktion verlagern, die bereits weitgehend gelöst und optimiert ist. Build-Automatisierung ist seit den 1990er Jahren Stand der Technik und die Herausforderungen, CI/CD (Continuous Integration und Continuous Deployment) richtig einzurichten, sind trivial im Vergleich zur eigentlichen Herausforderung, die da lautet: Eine optimale Nutzung der teuersten und knappsten Ressource in der Softwareproduktion zu gewährleisten - der Zeit der Entwickler.
Wir verwenden die Metapher der Fabrik, um uns auf den anspruchsvollen Teil der Softwareentwicklung zu konzentrieren: die intellektuelle Arbeit der Softwareentwickler, die Anforderungen/Spezifikationen in Code umsetzen.

Die statische Codeanalyse bezieht sich auf Methoden, die den Code im Hinblick auf strukturelle Aspekte analysieren. Der Zweck der statischen Codeanalyse besteht nicht darin, zu prüfen, ob sich ein Softwaresystem zur Laufzeit wie erwartet verhält. Eine solche Analyse wird durch dynamische Analyse oder Tests durchgeführt. So wie wir die "Build-Automatisierung" aus dem Anwendungsbereich der Softwarefabrik-Metapher ausgeschlossen haben, schließen wir auch alles, was mit dem Laufzeitverhalten zu tun hat, aus dem Anwendungsbereich aus. Wir tun dies in diesem Artikel, um nicht von der eigentlichen Herausforderung in einer Softwarefabrik abzulenken: der optimalen Nutzung der Entwicklerzeit.
Um das Ziel der statischen Code-Analyse besser zu verstehen, betrachten wir ihr Gegenstück in der Hardware-Produktion. Stellen Sie sich dazu eine Hardware-Fabrik vor, die Radios herstellt. Dann würde die statische Codeanalyse die strukturelle Qualität des zusammengebauten Radios überprüfen. Sind Widerstände, Kondensatoren und Drähte gut verlötet?
Kurz gesagt: Statische Code-Analyse befasst sich mit der strukturellen Qualität des gelieferten Outputs der Software-Fabrik, aber sie hilft nicht, Einblick in den Produktionsprozess selbst zu gewinnen und ist nicht in der Lage, ineffiziente Nutzung der Entwicklerzeit zu vermeiden. Passenderweise würde auch in der Hardwareproduktion niemand versuchen, den Produktionsprozess zu optimieren, indem er sich nur die ausgelieferten Geräte ansieht.
Wir haben oben die konzeptionellen Unterschiede zwischen Hardware- und Software-Fabriken erörtert. Es gibt einen weiteren Unterschied: Der Produktionsprozess von Hardware ist ein linearer Prozess, der immer bei Null beginnt. Die Eingabe wird in eine Ausgabe umgewandelt. Das ist einfach. Die Softwareproduktion hingegen ist ein iterativer Prozess, bei dem jeder Produktionszyklus auf demselben Material stattfindet. Neue Anforderungen als Input werden in eine sich entwickelnde Codebasis eingebaut.
Die Metapher der Hardware-Fabrik zerbricht leider, wenn man den iterativen Charakter der Software-Produktion in Betracht zieht. Eine solche Hardware-Fabrik würde nur ein einziges Radio produzieren und das Radio in jedem Produktionszyklus neu verlöten und verdrahten. Aber stellen wir uns einmal eine solche ungewöhnliche Radiofabrik vor. Dann ginge es bei der statischen Codeanalyse darum, zu prüfen, wie gut Kondensatoren, Widerstände und Drähte verlötet sind. Aber es ginge auch um einen anderen Aspekt der Strukturqualität: die Verständlichkeit der inneren Struktur des Radios.
Ein Maschinenbauingenieur, der einem Radio Bluetooth-Funktionen hinzufügen soll, würde sehr langsam und vorsichtig arbeiten, wenn er mit einem spaghettiartigen Kabelchaos im Inneren des Radios konfrontiert wird. Und genau das erleben Softwareentwickler, wenn sie eine Codebasis "öffnen", der es an einer nachvollziehbaren inneren Struktur mangelt: zu große und monolithische Codeeinheiten (Platinen) mit weit verzweigten Abhängigkeiten (Drähte) und langen Methoden mit undokumentierten komplexen if-else-Strukturen (elektronische Elemente, deren Zweck und Funktionen die Ingenieure zurückentwickeln müssen).
Warum wird eine Codebasis nicht sofort refaktorisiert und bereinigt, wenn es so offensichtlich ist, dass eine komplexe innere Struktur sich so negativ auf die Leistung der Fabrik auswirkt? Die Argumentation lautet:
Das Problem ist also ein Kommunikationsproblem zwischen der Geschäftsseite und der Entwicklungsseite. Aus diesem Dilemma ist der Begriff "technische Schulden" entstanden. Die Entwicklungsseite versucht, in der Sprache der Geschäftsseite (Geld) zu erklären, dass künftige Probleme angehäuft werden. Leider hat das Konzept der technischen Schulden Unzulänglichkeiten:
Folglich reicht es nicht aus, statische Code-Analysen durchzuführen, um schwer verständliche Code-Bereiche zu identifizieren. Das Problem besteht darin, der Geschäftsseite viel überzeugendere Argumente vorzulegen, um sie davon zu überzeugen, auf einige ihrer Funktionswünsche zu verzichten und Refactorings zuzulassen. Die Anzahl der von einem statischen Analysewerkzeug gefundenen Regelverstöße ist in der Regel ein wenig überzeugendes Argument.
Aufgrund des Zielkonflikts zwischen Unternehmen und Entwicklern wird die statische Code-Analyse in der Regel an einem Punkt in die Software-Entwicklung einbezogen, der ausschließlich in den Zuständigkeitsbereich der Entwickler fällt: die Definition von Codierungsregeln. Hier kann die statische Code-Analyse jedoch nur dazu beitragen, den Status quo zu erhalten, d. h. keine neuen Verstöße gegen die Kodierungsregeln. Jede Investition in die Beseitigung bestehender Regelverstöße würde eine "Verhandlung" mit der Geschäftsseite erfordern.
Wie Sie im vorherigen Abschnitt gesehen haben: Die statische Code-Analyse ist konzeptionell nicht geeignet, um Einblicke in den Software-Produktionsprozess selbst zu gewinnen. Sie kann daher auch nicht dazu beitragen, die Zeit der Entwickler, die knappste Ressource im Produktionsprozess, optimal zu nutzen. Was nun? Die Antwort liegt auf der Hand: Ein Perspektivwechsel. Wir verlagern den Schwerpunkt vom Code auf die Codierung und messen direkt, wie die Zeit der Softwareentwickler genutzt wird. Der Ansatz klingt einfach, ist aber in der Praxis schwierig. wird. Der Ansatz klingt einfach, ist aber in der Praxis schwierig.
Die Gründe dafür sind vielfältig:
Eine Lösung, die die effiziente Nutzung der Entwicklerzeit misst, kann sich daher nicht auf die Zeiterfassungsdaten verlassen. Welche anderen Daten könnten als Näherungswert für die Zeit genommen werden?
Glücklicherweise wurde kürzlich ein analytischer Ansatz entwickelt, der die oben genannten Hindernisse überwindet. Mit ihm kann der Fluss der Entwicklerzeit aus den technischen Datenspuren rekonstruiert werden, die bereits automatisch in den Softwareentwicklungsinfrastruktur-Tools wie Codeversionierungssystemen (Git, Subversion, MKS, Mercurial, ClearCase, ...) gesammelt werden.
Interessanterweise ist es trotz der Tatsache, dass der analytische Ansatz den Fluss der Entwicklerzeit aus den Aktivitäten der Softwareentwickler rekonstruiert, nicht erforderlich zu wissen, wer jeder einzelne Entwickler ist. Das heißt, es werden keine personenbezogenen Daten verarbeitet. Es ist sozusagen die sprichwörtliche "Quadratur des Kreises": Die Möglichkeit, den Zeitfluss der Entwickler zu sehen, ohne das Verhalten der einzelnen Entwickler verfolgen zu können. Wir betonen dies, weil ein Ansatz, mit dem die Leistung einzelner Entwickler nachverfolgt werden könnte, für Betriebsräte in Europa ein No-Go wäre.
Mit den Informationen über den Fluss der Entwicklerzeit können wir weitere Analysemethoden hinzufügen, um Ineffizienzen im Softwareproduktionsprozess aufzudecken. Die folgende Grafik zeigt, wie die Entwicklerzeit durch verschiedene Ineffizienzen verbraucht wird und nur ein Bruchteil der Entwicklerzeit für die Wertschöpfung des Unternehmens übrig bleibt. Ineffizienzen umfassen:
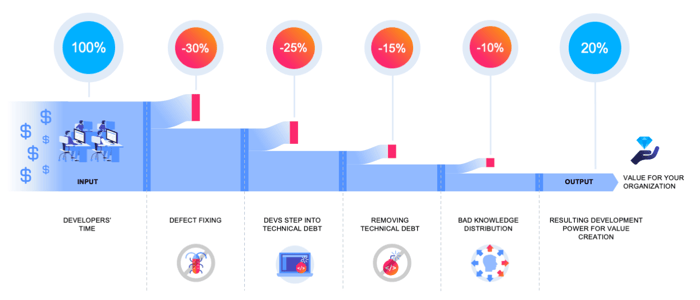
Die Fähigkeit, die Effizienz einer Softwarefabrik mit solchen KPIs zu quantifizieren, ermöglicht es dem Management und den beteiligten Teams, Ineffizienzen zu erkennen und die Organisation zu weniger Verlusten zu führen. In der Praxis arbeiten Softwarefabriken - im Vergleich zu Hardwarefabriken - oft auf einem niedrigen Effizienzniveau und haben ein großes Optimierungspotenzial. Der Grund dafür ist, dass es bisher keinen analytischen Ansatz zur Messung der Effizienz in der Softwareproduktion gab.Ein weiterer Vorteil dieses datengestützten Ansatzes ist, dass die Erkenntnisse aus technischen Rohdaten abgeleitet werden. So können wir die Ursachen für Ineffizienzen zurückverfolgen, indem wir uns in die technischen Datendetails vertiefen. So können wir beispielsweise feststellen, wo in der Code-Architektur Aktivitäten zur Fehlerbehebung stattfinden.
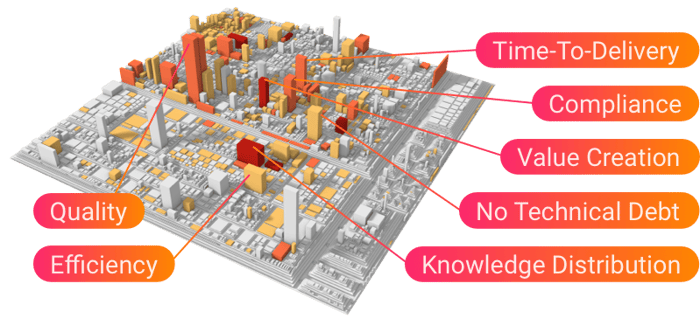
Auf diese Weise erhalten die Softwarearchitekten und Teamleiter ein präzises Röntgenbild der problematischen Hotspots im Code. Eine leistungsstarke und auffällige Methode, um Hotspots in der Code-Architektur aufzudecken, ist die Visualisierung von Code als Stadt. Gebäude sind Codeeinheiten, und die Stadtstruktur spiegelt die Struktur der technischen Module wider. Höhe und Farbe der Code-Gebäude werden verwendet, um Ineffizienz-KPIs darzustellen, z. B. den Zeitaufwand der Entwickler für die Fehlerbehebung im Code-Gebäude.
Der Vorteil einer solchen Visualisierung besteht darin, dass die technischen Informationen sowohl von den technischen Code-Experten als auch von den Managern interpretiert werden können. Sie hilft, die Kommunikationskluft zwischen Geschäfts- und Entwicklungsseite zu überbrücken (siehe Abschnitt oben).
Der analytische Ansatz funktioniert auf zwei Ebenen:
Im Ergebnis ermöglicht der Analytics-Ansatz den Softwarefabriken erstmals die Etablierung eines datengesteuerten kontinuierlichen Verbesserungszyklus, bei dem das "Besserwerden" nahtlos in die tägliche Arbeit der Softwarefabrik eingebettet ist und die analytikbasierten Erkenntnisse und KPIs sicherstellen, dass die Fabrik auf eine immer höhere Produktionsexzellenz ausgerichtet ist.