



Published in “AI Trendletter” (in German). Translated in March 2021 by Brandon Lewis.
The Hasso Plattner Institute for Digital Engineering (HPI) is researching the application of artificial intelligence (AI) in software engineering at the new AI Lab for Software Engineering. The goal is to identify those AI approaches for the management of complex software projects with which the greatest possible efficiency potentials can be realized.
Prof. Dr. Jürgen Döllner, the head of the AI Lab, explains the background in an interview. He also describes the goals of the planned HPI study "AI for Software Engineering", in which interested companies that want to learn about the potential of AI for their own software engineering can participate. The submitted software development projects should have been running for at least two years and involve ten or more developers. The selected companies will receive a quick introduction to the future topic of "AI in software engineering" with guidelines for setting up their own AI strategy, an analysis and evaluation of software development based on the submitted project, and benchmarking within the field of participants.
Prof. Döllner, AI is one of the hot topics of our time. Why has AI not yet been used in software engineering, of all places?
Prof. Dr. Jürgen Döllner: The first practical applications of AI were in optical character recognition – to recognize handwritten addresses, for example. In many applications, however, AI could not fully develop its effect because the performance of the hardware was not yet sufficient or the data was not of sufficient quality. Ultimately, AI relies on high computing power and Big Data. Without meaningful training data, for example, AI cannot make sufficiently accurate decisions. That's a big reason why machine learning didn't spread immediately.
In software engineering itself, AI has hardly been applied so far. There has never been a real paradigm shift here: Even in the "agile age", software production is still more like an artisan craft than an industrial process with plannable, calculable results.
Today, however, there is plenty of data that could be analyzed using Big Data methods. Each individual software tool brings its own repository with it.
It is indeed a peculiar situation: In repositories and all the other tools, we have excellent, precise data about all essential aspects of software development. We know at any point in time who changed which code on which module. We also know when and where there was a bug and who handled it.
%20-%20SOFTWARE%20MANUFACTORING%20PROCESS.png?width=600&name=What%20is%20seerene(V12)%20-%20SOFTWARE%20MANUFACTORING%20PROCESS.png)
These and countless other data have been collected for decades. But there has simply been a lack of realization that valuable knowledge can be generated from this data: The idea of "software analytics" is relatively new and, to date, has hardly been put into practice. The data is mostly only used by the experts who operate the tools in question.
If I look at the data in its entirety, I can draw conclusions about the evolution, quality, and risks of my software project and my development team, for example. This is what software analytics is all about: systematically evaluating the repositories to generate higher-level knowledge that helps all those responsible in the software production process, especially software management.
Big data always raises the question of who has sovereignty over the data and whether you want to give away your own data. To what extent do such concerns play a role in software engineering?
When analyzing software projects, we only use data from the respective project. Here, ownership is clear from the outset. However, the traditional software manufacturing process is highly structured and characterized by a silo structure in terms of data: There is no universal database - rather, we have different stadiums, each with its own data management. Therefore, the first step towards software analytics is to connect all data silos and to transfer their content into a common information space about software development.
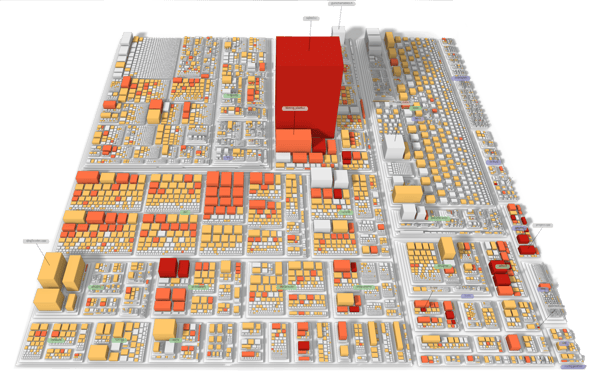
Visualization of a complex system as a software map
However, anyone who leaves it at that will not be exploiting the full potential of software analytics. For this, it is necessary to collect data on many projects and to build up knowledge detached from the individual projects, anonymized as it were. Our associated partner Seerene has a knowledge base from the ongoing, systematic scanning of several 10,000 open source projects. The data obtained describes the software on an abstract level: For each module, a so-called high-dimensional feature vector is generated, which essentially reflects properties and states of the module for each point in time. In this way, statements about evolution and software quality can be made independently of the source code.
How does the individual company benefit from this knowledge aggregated across projects?
A knowledge base generated from so many projects can help to classify and improve one's own development. Then questions can be answered such as: Is my approach to software development statistically promising for my task? Does it mean more or less risk in the medium and long term?
If I look at past projects whose progress I know, I can draw conclusions about the current project. This creates an early warning system that points out dangers and difficulties or identifies consequences that I will face in the future. Then I can assess whether or not my software has desired characteristics, for example in terms of stability, portability and freedom from errors.
Of course, in the end it is always just a matter of probabilities. That is why the knowledge base is crucial: It is the prerequisite for the reliable prediction of properties of software systems. With it, I can predict quality aspects, consequences and defect probabilities. And I can make statements about the quality of the software architecture, but also about the composition of the development team and its strengths.
This goes far beyond classic big data applications. At what point does AI come into play?
Statements about the future always contain a degree of uncertainty that is difficult to formulate using simple rules. For this, I need the entire repertoire of prediction methods offered by AI. Since no two software systems are alike, I have to work with this inherent fuzziness, I have to determine congruencies.
Dealing with fuzziness and incompleteness is an essential property of AI. This is exactly what I need for prediction when it comes to my own software system. In the end, I have thereby created the prerequisites for systematic benchmarking.
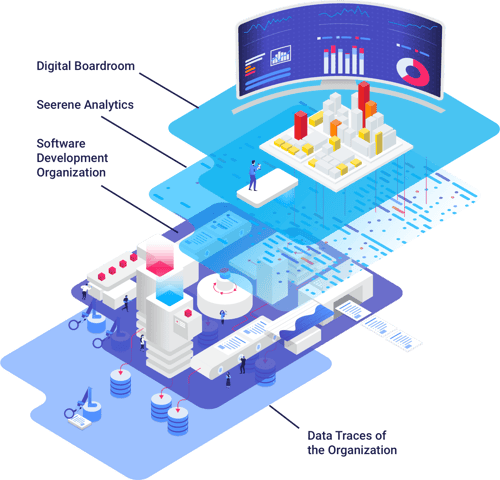
Management of a Software Development Organization with Software Analytics
Where are we with AI adoption in software engineering? Are we talking about practical applications or university research?
AI for software engineering has been developing rapidly in recent years. We are thus long out of the prototype stage. Hardware and software in the AI field are fortunately generic and can be adapted to almost all application fields. This is the reason for the high development speed, because we do not need any application field-specific technologies, but can always fall back on a common core. That is why we can already build industry-stable solutions for software analytics today.
To this end, the AI Lab, which researches methods and concepts of AI for IT systems engineering, went into operation at HPI on October 1, 2019. Here, researchers have the opportunity to explore their procedures and methods in a scalable hardware and software environment. The focus is on software engineering, on what aspects play a role in the development of AI systems. For this, it is important for us to obtain industrial data and to be able to investigate industry-relevant issues. Our associated partners provide this access - Seerene, for example, can contribute large industrial software projects. This results in unique data that a university would otherwise not have at its disposal.
For the current AI study, you are calling on companies to participate. Is it about you getting access to project data, or what exactly is the role of the participants?
The AI study has two goals: On the one hand, we want to inspire companies to give us a selected project as the object of study. On the other hand, it has the purpose that companies get to know the possibilities and limits of AI for software engineering in concrete terms. We want to observe these projects for a year and generate conclusions that we will discuss with the companies. In this way, the companies will be able to assess more precisely where in the software development process the use of AI makes sense for them and where it does not.
So the advantage for companies is to gain initial experience and try things out?
It is a research project in which companies participate. They get access to current research results and can orient themselves earlier than others to what extent and where AI can play a role for their own software developments. The implementation in practice is carried out by our industry partner Seerene with its software analytics platform.
We assume that measurable improvements can already be achieved in the companies as part of the study. It seems important to us to put companies in touch with tools to see how they can be integrated into internal processes.
We must be clear that no company can afford to forego productivity gains from the use of AI in software engineering in the medium term. Anyone who doesn't design their software development in line with the times and use modern technology for this purpose in the next few years will hardly be able to stand up to the competition. We are now talking about a paradigm shift: For companies, it is no longer a matter of introducing yet another new programming language, a new framework, a new database or a new process model. In the next few years, it will be a matter of optimizing and redesigning the complex manufacturing process of software with AI.
And with this paradigm shift, study participants then enjoy the benefit of early entry?
Exactly – they have the advantage of the early use of this technology to make their own software development competitive and fit for the future. This paradigm shift will play a major role in determining whether companies can be successful with their software development in the future.
How can you participate?
The study starts in January, until then we are accepting project proposals. We then discuss with the applicants whether their project is suitable - it should have a certain minimum size and have already reached a certain runtime. Then we ask which software repositories will be used to ensure that we can implement the connection to our analysis systems. If everything fits, we observe, interpret and analyze the software development processes with AI-based methods from January. At the end, we evaluate and improve them.
Prof. Döllner, thank you very much for the interview!


